X-Pert for Drug + Gene Co-Training (Multi-Perturbation)
This notebook adapts the drug-only workflow to support joint training with drug and gene perturbations.
Key points:
Unified
pert_mode = 'drug_gene'for mixed perturbationsGene embeddings (e.g., scGPT token vectors) and drug embeddings (e.g., ECFP/GROVER) are both loaded
Batch-level
drug_masksplits perturbations by type to build two modality-specific embedding tensorsOptional dosage modeling for drugs only
Compatible with scGPT-based encoder and scFlamingo cross-modality design
1. Imports
[1]:
# Core
import os, json, time, copy, warnings
from pathlib import Path
from typing import Dict
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
from torch import nn
from tqdm import tqdm
import matplotlib.pyplot as plt
# X-Pert package
import xpert
from xpert.models import TransformerGenerator
from xpert.loss import masked_relative_error, masked_mse_loss, masked_huber_loss
from xpert.external_model.scgpt.gene_tokenizer import GeneVocab
from xpert.external_model.gears.inference import compute_metrics
# from xpert.data import Byte_Pert_Data
# Utils
from xpert.utils import fix_seed, merge_plot
from xpert.external_model.scgpt.util import set_seed, map_raw_id_to_vocab_id, add_file_handler
2. Global Settings and Logger
[2]:
# Reproducibility
set_seed(42)
fix_seed(2024)
# Logger to file
save_root = Path("./L1000_phase1_cotrain/model_mode_scFlamingo_drug_gene_v1")
save_root.mkdir(parents=True, exist_ok=True)
logger = xpert.logger
add_file_handler(logger, save_root / "run.log")
logger.info(f"Running on {time.strftime('%Y-%m-%d %H:%M:%S')}")
# Plot default
plt.rcdefaults()
warnings.filterwarnings("ignore")
INFO:xpert:Running on 2025-11-03 17:05:57
3. Data Configuration
[3]:
# Dataset and split
prefix = 'L1000_phase1_cotrain' # or 'sciplex_3', etc.
add_control = False
# Split strategies (for L1000 datasets)
# data_split_0: random perts
# data_split_1: split drugs
# data_split_2: split cell types
split_col = 'data_split_1'
# Paths
# Base data directory
data_dir = Path('../../data') / prefix
pert_data_version = 'pert_data.pkl'
# Drug embedding directory (local repo data)
drug_embed_dir = data_dir
# Gene embedding directory (external scGPT-based embeddings), absolute path
# These are used to embed gene perturbations so they align with scGPT vocabulary space
# If you have a local copy, adjust path accordingly
gene_embed_file = Path('../../data/L1000_phase1_cotrain/pert_embed.csv')
# scGPT pretrained model
load_model_dir = Path('../../data/scGPT_human')
model_config_file = load_model_dir / 'args.json'
model_file = load_model_dir / 'best_model.pt'
vocab_file = load_model_dir / 'vocab.json'
4. Hyperparameters and Modes
[4]:
# Training hyperparameters
batch_size = 64
eval_batch_size = 64
log_interval = 100
# Cell encoder hyperparameters
embsize = 512
d_hid = 512
nlayers = 12
nhead = 8
n_layers_cls = 3
dropout = 0.2
use_fast_transformer = True
amp = True
# Adjust based on available GPUs
device_ids = [0]
# Perturbation settings
pert_mode = 'drug_gene' # joint training for drug + gene
pert_flag_mode = False # use binary flags when True; set False for co-train
attn_gate_mode = True
load_cxg_weight = True
mask_mode = True
use_scgpt_layer = True
use_scgpt_input = True
add_token = True
init_mode = False
cross_mode = True
pert_type_mode = True
delta_mode = False
# Co-train alignment settings (match scFlamingo_drug_v27)
co_train_mode = 1
align_loss = 'mmd'
alpha_mmd = 0.2
# Drug embedding settings
drug_embed_mode = 'ecfp' # 'grover' | 'rdkit' | 'morgan' | 'ecfp' | 'chemberta_st' | 'grover+rdkit'
# Dosage settings (applied to drugs only)
dosage_mode = False # v27 disables dosage
dosage_mode_type = -1 # -1 disables; 0/1/2 refer to strategies if enabled
# Scheduler
epochs = 20
lr = 1e-5 # v27 uses lower LR
scheduler_type = 'cosine_warm' # v27
schedule_interval = 5
# Gradient clipping
max_norm = 1.0
# Control whether to copy encoder weights into encoder_plus when adding tokens
load_encoder_plus = True
include_zero_gene = "all"
5. Scheduler and Training/Eval Routines
[5]:
from torch.optim.lr_scheduler import LambdaLR
import math
def get_cosine_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps):
def lr_lambda(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
progress = (current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * progress)))
return LambdaLR(optimizer, lr_lambda)
def _split_perturbations_and_build_embeddings(
batch_perts,
batch_pert_types,
pert_embed_dict: Dict[str, np.ndarray],
gpt_emb_dim_gene: int,
gpt_emb_dim_drug: int,
dosage_list=None,
device=None,
):
"""
Build per-batch embedding tensors for gene and drug perturbations using a boolean drug_mask.
- batch_perts: list[str], format "drug1; gene2 | dose1; dose2" or "geneA; geneB | ctrl" for genes
- batch_pert_types: list[str], entries like 'trt_cp' (drug) or 'trt_sh.cgs' (gene)
- dosage_list: Optional[List[List[float]]] for drugs only, already aligned by sample
Returns: (batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask)
"""
B = len(batch_perts)
# tokenize perts and dosages
perts_split = [p.split(' | ')[0].split('; ') for p in batch_perts]
max_len = max(len(p) for p in perts_split) if B > 0 else 1
drug_mask = np.array(batch_pert_types) == 'trt_cp'
emb_gene = torch.zeros(sum(~drug_mask), max_len, gpt_emb_dim_gene).float()
emb_drug = torch.zeros(sum(drug_mask), max_len, gpt_emb_dim_drug).float()
pert_mask = torch.ones(B, max_len)
dos_pad = torch.zeros(sum(drug_mask), max_len).float()
# fill mask
for i, perts in enumerate(perts_split):
for j, pert in enumerate(perts):
pert_mask[i, j] = 0
# fill gene/drug embeddings separately (keep relative order)
gi = 0
di = 0
for idx, perts in enumerate(perts_split):
if drug_mask[idx]:
for j, pert in enumerate(perts):
emb_drug[di, j, :] = torch.tensor(np.array(pert_embed_dict[pert]))
if dosage_list is not None:
dos_pad[di, j] = dosage_list[idx][j]
di += 1
else:
for j, pert in enumerate(perts):
emb_gene[gi, j, :] = torch.tensor(np.array(pert_embed_dict[pert]))
gi += 1
if device is not None:
emb_gene = emb_gene.to(device)
emb_drug = emb_drug.to(device)
dos_pad = dos_pad.to(device)
pert_mask = pert_mask.to(device)
return emb_gene, emb_drug, pert_mask, dos_pad, drug_mask
def train(model: nn.Module, train_loader: torch.utils.data.DataLoader) -> None:
model.train()
total_loss, total_mse = 0.0, 0.0
start_time = time.time()
num_batches = len(train_loader)
for batch, batch_data in enumerate(tqdm(train_loader)):
batch_size = len(batch_data.y)
batch_data.to(device)
x: torch.Tensor = batch_data.x
ori_gene_values = x
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
target_gene_values = batch_data.y
# Prepare perts/types and optional dosages (only for drugs)
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
# Extract dosages for drug items only (log10(1 + dose)) if dosage_mode
dosage_list = None
if dosage_mode:
drug_indices = np.where(np.array(batch_pert_types) == 'trt_cp')[0]
dosage_list_full = [[np.log10(float(v) + 1) for v in s.split(' | ')[1].split('; ')] for s in batch_data.pert]
dosage_list = [dosage_list_full[i] for i in drug_indices]
batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask = _split_perturbations_and_build_embeddings(
batch_perts=batch_perts,
batch_pert_types=batch_pert_types,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
dosage_list=dosage_list if dosage_mode else None,
device=device,
)
# Select input genes
if include_zero_gene in ["all", "batch-wise"]:
if include_zero_gene == "all":
input_gene_ids = torch.arange(n_genes, device=device, dtype=torch.long)
else:
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
if len(input_gene_ids) > max_seq_len:
input_gene_ids = torch.randperm(len(input_gene_ids), device=device)[:max_seq_len]
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
target_values = target_gene_values[:, input_gene_ids]
if delta_mode:
target_values = target_values - input_values
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(input_values, dtype=torch.bool, device=device)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed=None, # not used in co-train; we pass per-modality below
pert_mask=pert_mask,
batch_dosages_pad=batch_dosages_pad if dosage_mode else None,
batch_pert_embed_gene=batch_pert_embed_gene,
batch_pert_embed_drug=batch_pert_embed_drug,
drug_mask=drug_mask,
CLS=False, CCE=False, MVC=False, ECS=False,
)
output_values = output_dict["mlm_output"]
masked_positions = torch.ones_like(input_values, dtype=torch.bool)
loss = loss_mse = criterion(output_values, target_values, masked_positions)
model.zero_grad()
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(
model.parameters(), max_norm, error_if_nonfinite=False if scaler.is_enabled() else True
)
scaler.step(optimizer)
scaler.update()
if scheduler_type in ['cosine', 'cosine_warm']:
scheduler.step()
total_loss += loss.item()
total_mse += loss_mse.item()
if batch % log_interval == 0 and batch > 0:
lr_ = scheduler.get_last_lr()[0] if scheduler_type != 'steplr' else scheduler.get_last_lr()[0]
ms_per_batch = (time.time() - start_time) * 1000 / log_interval
cur_loss = total_loss / log_interval
cur_mse = total_mse / log_interval
logger.info(f"| epoch {epoch:3d} | {batch:3d}/{num_batches:3d} batches | lr {lr_:07.6f} | ms/batch {ms_per_batch:5.2f} | loss {cur_loss:5.5f} | mse {cur_mse:5.5f} |")
total_loss = 0
total_mse = 0
start_time = time.time()
@torch.no_grad()
def evaluate(model: nn.Module, val_loader: torch.utils.data.DataLoader):
model.eval()
total_loss = 0.0
total_error = 0.0
for batch, batch_data in enumerate(val_loader):
batch_size = len(batch_data.y)
batch_data.to(device)
x: torch.Tensor = batch_data.x
ori_gene_values = x
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
target_gene_values = batch_data.y
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
dosage_list = None
if dosage_mode:
drug_indices = np.where(np.array(batch_pert_types) == 'trt_cp')[0]
dosage_list_full = [[np.log10(float(v) + 1) for v in s.split(' | ')[1].split('; ')] for s in batch_data.pert]
dosage_list = [dosage_list_full[i] for i in drug_indices]
batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask = _split_perturbations_and_build_embeddings(
batch_perts=batch_perts,
batch_pert_types=batch_pert_types,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
dosage_list=dosage_list if dosage_mode else None,
device=device,
)
if include_zero_gene in ["all", "batch-wise"]:
if include_zero_gene == "all":
input_gene_ids = torch.arange(n_genes, device=device)
else:
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
if len(input_gene_ids) > max_seq_len:
input_gene_ids = torch.randperm(len(input_gene_ids), device=device)[:max_seq_len]
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
target_values = target_gene_values[:, input_gene_ids]
if delta_mode:
target_values = target_values - input_values
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(input_values, dtype=torch.bool, device=input_values.device)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed=None,
pert_mask=pert_mask,
batch_dosages_pad=batch_dosages_pad if dosage_mode else None,
batch_pert_embed_gene=batch_pert_embed_gene,
batch_pert_embed_drug=batch_pert_embed_drug,
drug_mask=drug_mask,
do_sample=True,
)
output_values = output_dict["mlm_output"]
masked_positions = torch.ones_like(input_values, dtype=torch.bool, device=input_values.device)
loss = criterion(output_values, target_values, masked_positions)
total_loss += loss.item()
total_error += masked_relative_error(output_values, target_values, masked_positions).item()
return total_loss / len(val_loader), total_error / len(val_loader)
@torch.no_grad()
def pred_perturb_new(model, batch_data, include_zero_gene="batch-wise", gene_ids=None, amp=True):
model.eval()
device = next(model.parameters()).device
batch_data.to(device)
batch_size = len(batch_data.pert)
x: torch.Tensor = batch_data.x
ori_gene_values = x
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
dosage_list = None
if dosage_mode:
drug_indices = np.where(np.array(batch_pert_types) == 'trt_cp')[0]
dosage_list_full = [[np.log10(float(v) + 1) for v in s.split(' | ')[1].split('; ')] for s in batch_data.pert]
dosage_list = [dosage_list_full[i] for i in drug_indices]
batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask = _split_perturbations_and_build_embeddings(
batch_perts=batch_perts,
batch_pert_types=batch_pert_types,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
dosage_list=dosage_list if dosage_mode else None,
device=device,
)
if include_zero_gene in ["all", "batch-wise"]:
assert gene_ids is not None
if include_zero_gene == "all":
input_gene_ids = torch.arange(ori_gene_values.size(1), device=device)
else:
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(input_values, dtype=torch.bool, device=device)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed=None,
pert_mask=pert_mask,
batch_dosages_pad=batch_dosages_pad if dosage_mode else None,
batch_pert_embed_gene=batch_pert_embed_gene,
batch_pert_embed_drug=batch_pert_embed_drug,
drug_mask=drug_mask,
CLS=False, CCE=False, MVC=False, ECS=False,
do_sample=True,
)
output_values = output_dict["mlm_output"].float()
pred_gene_values = torch.zeros_like(ori_gene_values)
pred_gene_values[:, input_gene_ids] = output_values
if delta_mode:
pred_gene_values = input_values + pred_gene_values
return pred_gene_values
[15]:
@torch.no_grad()
def pred_perturb_new(
model,
batch_data,
include_zero_gene="batch-wise",
gene_ids=None,
amp=True,
):
"""
Args:
batch_data: a dictionary of input data with keys.
Returns:
output Tensor of shape [N, seq_len]
"""
model.eval()
device = next(model.parameters()).device
batch_data.to(device)
batch_size = len(batch_data.pert)
x: torch.Tensor = batch_data.x
# ori_gene_values = x[:, 0].view(batch_size, n_genes)
ori_gene_values = x
# pert_flags = x[:, 1].long().view(batch_size, n_genes)
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
drug_mask = np.array(batch_pert_types)=='trt_cp'
# batch_perts = [[i.split('+')[0]] if 'ctrl' in i else i.split('+') for i in batch_perts] # we first focus on the single perts
batch_perts = [i.split(' | ')[0].split("; ") for i in batch_perts]
# batch_dosages = [[np.log10(int(j)) for j in i.split(' | ')[1].split("; ")] for i in batch_data.pert]
batch_dosages = [[np.log10(float(j)+1) for j in i.split(' | ')[1].split("; ")] for i in np.array(batch_data.pert)[drug_mask]]
max_pert_len = max([len(perts) for perts in batch_perts])
batch_pert_embed_gene = torch.zeros(sum(~drug_mask), max_pert_len, gpt_emb_dim_gene).float()
batch_pert_embed_drug = torch.zeros(sum(drug_mask), max_pert_len, gpt_emb_dim_drug).float()
pert_mask = torch.ones(batch_size, max_pert_len)
batch_dosages_pad = torch.zeros(sum(drug_mask), max_pert_len).float()
# batch_pert_embed = torch.tensor(np.array([(pert_embed_dict[pert[0]]) for pert in batch_perts])).float()
for i, perts in enumerate(batch_perts):
for j, pert in enumerate(perts):
# batch_pert_embed[i, j, :] = torch.tensor(np.array(pert_embed_dict[pert]))
pert_mask[i, j] = 0
# batch_dosages_pad[i, j] = batch_dosages[i][j]
for i, perts in enumerate(np.array(batch_perts)[~drug_mask]):
for j, pert in enumerate(perts):
batch_pert_embed_gene[i, j, :] = torch.tensor(np.array(pert_embed_dict[pert]))
for i, perts in enumerate(np.array(batch_perts)[drug_mask]):
for j, pert in enumerate(perts):
batch_pert_embed_drug[i, j, :] = torch.tensor(np.array(pert_embed_dict[pert]))
batch_dosages_pad[i, j] = batch_dosages[i][j]
batch_pert_embed_gene = batch_pert_embed_gene.to(device)
batch_pert_embed_drug = batch_pert_embed_drug.to(device)
batch_dosages_pad = batch_dosages_pad.to(device)
if not dosage_mode:
batch_dosages_pad = None
if include_zero_gene in ["all", "batch-wise"]:
assert gene_ids is not None
if include_zero_gene == "all":
input_gene_ids = torch.arange(ori_gene_values.size(1), device=device)
else: # batch-wise
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(
input_values, dtype=torch.bool, device=device
)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed = None,
pert_mask = pert_mask,
batch_dosages_pad = batch_dosages_pad,
batch_pert_embed_gene = batch_pert_embed_gene,
batch_pert_embed_drug = batch_pert_embed_drug,
drug_mask = drug_mask,
CLS=False,
CCE=False,
MVC=False,
ECS=False,
do_sample=True,
)
output_values = output_dict["mlm_output"].float()
pred_gene_values = torch.zeros_like(ori_gene_values)
pred_gene_values[:, input_gene_ids] = output_values
if delta_mode:
pred_gene_values = input_values + pred_gene_values
return pred_gene_values
@torch.no_grad()
def eval_perturb_new(
loader: torch.utils.data.DataLoader, model: TransformerGenerator, device: torch.device
) -> Dict:
"""
Run model in inference mode using a given data loader
"""
model.eval()
model.to(device)
pert_cat = []
pred = []
truth = []
pred_de = []
truth_de = []
results = {}
logvar = []
for itr, batch in enumerate(loader):
batch.to(device)
pert_cat.extend(batch.pert)
with torch.no_grad():
p = pred_perturb_new(model, batch, include_zero_gene, gene_ids=gene_ids)
t = batch.y
pred.extend(p.cpu())
truth.extend(t.cpu())
# Differentially expressed genes
for itr, de_idx in enumerate(batch.de_idx):
pred_de.append(p[itr, de_idx])
truth_de.append(t[itr, de_idx])
# if debug_mode_1:
# break
# all genes
results["pert_cat"] = np.array(pert_cat)
pred = torch.stack(pred)
truth = torch.stack(truth)
results["pred"] = pred.detach().cpu().numpy().astype(np.float64)
results["truth"] = truth.detach().cpu().numpy().astype(np.float64)
pred_de = torch.stack(pred_de)
truth_de = torch.stack(truth_de)
results["pred_de"] = pred_de.detach().cpu().numpy().astype(np.float64)
results["truth_de"] = truth_de.detach().cpu().numpy().astype(np.float64)
return results
[7]:
def pairwise_dist2(a, b):
a2 = (a ** 2).sum(-1, keepdim=True)
b2 = (b ** 2).sum(-1, keepdim=True)
return a2 + b2.T - 2 * a @ b.T
def mmd_rbf(z_d, z_g, eps=1e-6):
z_d = z_d.squeeze().float()
z_g = z_g.squeeze().float()
dist2_dg = pairwise_dist2(z_d, z_g)
sigma2 = torch.quantile(dist2_dg, 0.5).clamp_min(eps)
k_dd = torch.exp(-pairwise_dist2(z_d, z_d) / (2 * sigma2)).mean()
k_gg = torch.exp(-pairwise_dist2(z_g, z_g) / (2 * sigma2)).mean()
k_dg = torch.exp(-dist2_dg / (2 * sigma2)).mean()
return k_dd + k_gg - 2 * k_dg
[8]:
# Override train/evaluate to include MMD alignment when enabled
def train(model: nn.Module, train_loader: torch.utils.data.DataLoader) -> None:
model.train()
total_loss, total_mse = 0.0, 0.0
start_time = time.time()
num_batches = len(train_loader)
for batch, batch_data in enumerate(tqdm(train_loader)):
batch_size = len(batch_data.y)
batch_data.to(device)
x: torch.Tensor = batch_data.x
ori_gene_values = x
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
target_gene_values = batch_data.y
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
dosage_list = None # v27 disables dosage
batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask = _split_perturbations_and_build_embeddings(
batch_perts=batch_perts,
batch_pert_types=batch_pert_types,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
dosage_list=dosage_list,
device=device,
)
if include_zero_gene in ["all", "batch-wise"]:
if include_zero_gene == "all":
input_gene_ids = torch.arange(n_genes, device=device, dtype=torch.long)
else:
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
if len(input_gene_ids) > max_seq_len:
input_gene_ids = torch.randperm(len(input_gene_ids), device=device)[:max_seq_len]
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
target_values = target_gene_values[:, input_gene_ids]
if delta_mode:
target_values = target_values - input_values
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(input_values, dtype=torch.bool, device=device)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed=None,
pert_mask=pert_mask,
batch_dosages_pad=None,
batch_pert_embed_gene=batch_pert_embed_gene,
batch_pert_embed_drug=batch_pert_embed_drug,
drug_mask=drug_mask,
CLS=False, CCE=False, MVC=False, ECS=False,
)
output_values = output_dict["mlm_output"]
masked_positions = torch.ones_like(input_values, dtype=torch.bool)
loss = loss_mse = criterion(output_values, target_values, masked_positions)
if align_loss == 'mmd' and 'latent_pert' in output_dict:
latent_pert = output_dict['latent_pert']
gene_mask = ~torch.tensor(drug_mask, dtype=torch.bool, device=latent_pert.device)
drug_mask_t = torch.tensor(drug_mask, dtype=torch.bool, device=latent_pert.device)
if drug_mask_t.any() and gene_mask.any():
loss_mmd = mmd_rbf(latent_pert[drug_mask_t], latent_pert[gene_mask])
else:
loss_mmd = latent_pert.new_tensor(0.)
loss = loss + alpha_mmd * loss_mmd
model.zero_grad()
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(
model.parameters(), max_norm, error_if_nonfinite=False if scaler.is_enabled() else True
)
scaler.step(optimizer)
scaler.update()
if scheduler_type in ['cosine', 'cosine_warm']:
scheduler.step()
total_loss += loss.item()
total_mse += loss_mse.item()
if batch % log_interval == 0 and batch > 0:
lr_ = scheduler.get_last_lr()[0] if scheduler_type != 'steplr' else scheduler.get_last_lr()[0]
ms_per_batch = (time.time() - start_time) * 1000 / log_interval
cur_loss = total_loss / log_interval
cur_mse = total_mse / log_interval
logger.info(f"| epoch {epoch:3d} | {batch:3d}/{num_batches:3d} batches | lr {lr_:07.6f} | ms/batch {ms_per_batch:5.2f} | loss {cur_loss:5.5f} | mse {cur_mse:5.5f} |")
total_loss = 0
total_mse = 0
start_time = time.time()
@torch.no_grad()
def evaluate(model: nn.Module, val_loader: torch.utils.data.DataLoader):
model.eval()
total_loss = 0.0
total_error = 0.0
for batch, batch_data in enumerate(val_loader):
batch_size = len(batch_data.y)
batch_data.to(device)
x: torch.Tensor = batch_data.x
ori_gene_values = x
if pert_mode == 'drug' and pert_flag_mode:
pert_flags = batch_data.pert_flags
else:
pert_flags = batch_data.pert_flags.long()
target_gene_values = batch_data.y
batch_perts = batch_data.pert
batch_pert_types = batch_data.pert_type
batch_pert_embed_gene, batch_pert_embed_drug, pert_mask, batch_dosages_pad, drug_mask = _split_perturbations_and_build_embeddings(
batch_perts=batch_perts,
batch_pert_types=batch_pert_types,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
dosage_list=None,
device=device,
)
if include_zero_gene in ["all", "batch-wise"]:
if include_zero_gene == "all":
input_gene_ids = torch.arange(n_genes, device=device)
else:
input_gene_ids = (
ori_gene_values.nonzero()[:, 1].flatten().unique().sort()[0]
)
if len(input_gene_ids) > max_seq_len:
input_gene_ids = torch.randperm(len(input_gene_ids), device=device)[:max_seq_len]
input_values = ori_gene_values[:, input_gene_ids]
input_pert_flags = pert_flags[:, input_gene_ids]
target_values = target_gene_values[:, input_gene_ids]
if delta_mode:
target_values = target_values - input_values
mapped_input_gene_ids = map_raw_id_to_vocab_id(input_gene_ids, gene_ids)
mapped_input_gene_ids = mapped_input_gene_ids.repeat(batch_size, 1)
src_key_padding_mask = torch.zeros_like(input_values, dtype=torch.bool, device=input_values.device)
with torch.cuda.amp.autocast(enabled=amp):
output_dict = model(
mapped_input_gene_ids,
input_values,
input_pert_flags,
src_key_padding_mask=src_key_padding_mask,
batch_pert_embed=None,
pert_mask=pert_mask,
batch_dosages_pad=None,
batch_pert_embed_gene=batch_pert_embed_gene,
batch_pert_embed_drug=batch_pert_embed_drug,
drug_mask=drug_mask,
do_sample=True,
)
output_values = output_dict["mlm_output"]
masked_positions = torch.ones_like(input_values, dtype=torch.bool, device=input_values.device)
loss = criterion(output_values, target_values, masked_positions)
if align_loss == 'mmd' and 'latent_pert' in output_dict:
latent_pert = output_dict['latent_pert']
gene_mask = ~torch.tensor(drug_mask, dtype=torch.bool, device=latent_pert.device)
drug_mask_t = torch.tensor(drug_mask, dtype=torch.bool, device=latent_pert.device)
if drug_mask_t.any() and gene_mask.any():
loss_mmd = mmd_rbf(latent_pert[drug_mask_t], latent_pert[gene_mask])
else:
loss_mmd = latent_pert.new_tensor(0.)
loss = loss + alpha_mmd * loss_mmd
total_loss += loss.item()
total_error += masked_relative_error(output_values, target_values, masked_positions).item()
return total_loss / len(val_loader), total_error / len(val_loader)
6. Data Loading and Tokenization
[9]:
seed = 2024
bs_train = 32
bs_test = bs_train * 2
# Load preprocessed pert_data object
import pickle
pert_data = pickle.load(open(data_dir / pert_data_version, 'rb'))
# Set var_genes
pert_data.var_genes = pert_data.adata_split.var_names
# Build X-Pert training datasets
# For co-train, keep split_col consistent with L1000 drug-split for comparability
pert_data.get_Data_scgpt_2(
num_de_genes=pert_data.num_de_genes,
dataset_name=['train', 'test', 'val'],
add_control=add_control,
split_col=split_col,
pert_flag_mode=pert_flag_mode,
drug_embed_dir=drug_embed_dir,
pert_type_mode=pert_type_mode,
)
# Attach full AnnData and gene names
pert_data.adata = pert_data.adata_split
pert_data.adata.var["gene_name"] = pert_data.adata.var_names
# DataLoaders
trainloader, testloader, valloader = pert_data.get_dataloader(
mode='all',
bs_train=int(bs_train)*max(1, len(device_ids)),
bs_test=int(bs_test)*max(1, len(device_ids))
)
100%|██████████| 8461/8461 [00:19<00:00, 441.48it/s]
100%|██████████| 944/944 [00:02<00:00, 471.76it/s]
0it [00:00, ?it/s]
========== get Data_scGPT finished!
7. Load Gene and Drug Embeddings
[10]:
# Load gene embeddings (scGPT token space) and drug embeddings
assert gene_embed_file.exists(), f"Gene embedding file not found: {gene_embed_file}"
gene_embed = pd.read_csv(gene_embed_file, sep=',', index_col=0)
# Load drug embeddings based on mode
if drug_embed_mode == 'grover':
drug_embed = pd.read_csv(drug_embed_dir / 'embed_grover.csv', sep=',', index_col=0)
elif drug_embed_mode == 'rdkit':
drug_embed = pd.read_csv(drug_embed_dir / 'embed_rdkit.csv', sep=',', index_col=0)
elif drug_embed_mode == 'morgan':
drug_embed = pd.read_csv(drug_embed_dir / 'embed_morgan.csv', sep=',', index_col=0)
elif drug_embed_mode == 'ecfp':
drug_embed = pd.read_csv(drug_embed_dir / 'embed_ecfp.csv', sep=',', index_col=0)
elif drug_embed_mode == 'chemberta_st':
drug_embed = pd.read_csv(drug_embed_dir / 'embed_chemberta_st.csv', sep=',', index_col=0)
elif drug_embed_mode == 'grover+rdkit':
emb1 = pd.read_csv(drug_embed_dir / 'embed_grover.csv', sep=',', index_col=0)
emb2 = pd.read_csv(drug_embed_dir / 'embed_rdkit.csv', sep=',', index_col=0)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
drug_embed = pd.concat([emb1, emb2], axis=0)
drug_embed = pd.DataFrame(scaler.fit_transform(drug_embed.T).T, index=drug_embed.index, columns=drug_embed.columns)
else:
raise ValueError(f"Unknown drug_embed_mode: {drug_embed_mode}")
# Build joint pert_embed_dict for both gene and drug perturbations
# Identify unique gene and drug perts from the filtered perturbation list
all_perts = np.array(pert_data.filter_perturbation_list)
all_perts_names = [i.split(' | ')[0] for i in all_perts]
# Split by observed pert types from obs if available
obs = pert_data.adata_split.obs
gene_perts = obs.loc[obs['pert_type']=='trt_sh.cgs', 'perturbation_new'].unique()
drug_perts = obs.loc[obs['pert_type']=='trt_cp', 'perturbation_new'].unique()
pert_embed_dict: Dict[str, np.ndarray] = {}
np.random.seed(2024)
# Gene embeddings
for pert in gene_perts:
if pert in gene_embed.columns:
pert_embed_dict[pert] = gene_embed.loc[:, pert].values
else:
logger.warning(f'{pert} not in gene_embed, using random gene embedding proxy')
pert_embed_dict[pert] = gene_embed.loc[:, np.random.choice(gene_embed.columns, 1)[0]].values
# Drug embeddings
for pert in drug_perts:
if pert in drug_embed.columns:
pert_embed_dict[pert] = drug_embed.loc[:, pert].values
else:
logger.warning(f'{pert} not in drug_embed, using random drug embedding proxy')
pert_embed_dict[pert] = drug_embed.loc[:, np.random.choice(drug_embed.columns, 1)[0]].values
# Embedding dims per modality
gpt_emb_dim_gene = gene_embed.shape[0]
gpt_emb_dim_drug = drug_embed.shape[0]
logger.info(f"Loaded {len(gene_perts)} gene perts (dim={gpt_emb_dim_gene}) and {len(drug_perts)} drug perts (dim={gpt_emb_dim_drug})")
INFO:xpert:Loaded 3302 gene perts (dim=1536) and 6082 drug perts (dim=2048)
8. Vocabulary, Tokens and Sequence Setup
[11]:
# Load vocab and extend if needed
vocab = GeneVocab.from_file(vocab_file)
special_tokens = ["<pad>", "<cls>", "<eoc>"]
for s in special_tokens:
if s not in vocab:
vocab.append_token(s)
vocab_ori = copy.deepcopy(vocab)
if add_token:
add_genes = np.setdiff1d(pert_data.adata.var_names, list(vocab.get_stoi().keys()))
for gene in add_genes:
if gene not in vocab:
vocab.append_token(gene)
pert_data.adata.var["id_in_vocab"] = [1 if gene in vocab else -1 for gene in pert_data.adata.var_names]
gene_ids_in_vocab = np.array(pert_data.adata.var["id_in_vocab"])
logger.info(f"match {np.sum(gene_ids_in_vocab >= 0)}/{len(gene_ids_in_vocab)} genes in vocabulary of size {len(vocab)}.")
# Build token ids for input genes
genes = pert_data.adata.var["gene_name"].tolist()
vocab.set_default_index(vocab["<pad>"])
gene_ids = np.array([vocab[g] if g in vocab else vocab["<pad>"] for g in genes], dtype=int)
n_genes = len(genes)
# Sequence length
max_seq_len = 6000
INFO:xpert:match 978/978 genes in vocabulary of size 60726.
[ ]:
9. Build Model, Optimizer and Scheduler
[12]:
# Rebuild model and optim to enforce v27 settings
with open(model_config_file, 'r') as f:
model_configs = json.load(f)
embsize = model_configs.get('embsize', embsize)
d_hid = model_configs.get('d_hid', d_hid)
n_layers_cls = model_configs.get('n_layers_cls', n_layers_cls)
ntokens = len(vocab_ori)
model = TransformerGenerator(
ntokens,
embsize,
nhead,
d_hid,
nlayers,
nlayers_cls=n_layers_cls,
n_cls=1,
vocab=vocab,
dropout=dropout,
pad_token='<pad>',
pad_value=0,
pert_pad_id=2,
use_fast_transformer=use_fast_transformer,
pert_embed_dict=pert_embed_dict,
gpt_emb_dim=gpt_emb_dim_gene,
model_mode='scFlamingo_drug_v27',
attn_gate_mode=attn_gate_mode,
pert_mode=pert_mode,
drug_embed_mode=drug_embed_mode,
pert_flag_mode=pert_flag_mode,
use_scgpt_layer=use_scgpt_layer,
use_scgpt_input=use_scgpt_input,
mask_mode=mask_mode,
add_token=add_token,
init_mode=init_mode,
dosage_mode_type=dosage_mode_type,
cross_mode=cross_mode,
gpt_emb_dim_gene=gpt_emb_dim_gene,
gpt_emb_dim_drug=gpt_emb_dim_drug,
co_train_mode=co_train_mode,
align_loss=align_loss,
)
if load_cxg_weight:
load_param_prefixs = ["encoder", "value_encoder", "transformer_encoder"]
state = torch.load(model_file)
model_dict = model.state_dict()
pretrained_dict = {k: v for k, v in state.items() if any([k.startswith(p) for p in load_param_prefixs])}
model_dict.update(pretrained_dict)
_missing = model.load_state_dict(model_dict, strict=False)
logger.info(f"Missing keys: {len(_missing.missing_keys)} | Unexpected keys: {len(_missing.unexpected_keys)}")
if add_token and load_encoder_plus:
with torch.no_grad():
n = model.encoder.embedding.num_embeddings
model.encoder_plus.embedding.weight[:n] = model.encoder.embedding.weight
model.encoder_plus.enc_norm.weight[:] = model.encoder.enc_norm.weight
model.encoder_plus.enc_norm.bias[:] = model.encoder.enc_norm.bias
pretrained_embed = model.encoder.embedding.weight
mean = pretrained_embed.mean(dim=0)
std = pretrained_embed.std(dim=0)
m = model.encoder_plus.embedding.num_embeddings - n
if m > 0:
model.encoder_plus.embedding.weight[n:] = torch.normal(mean=mean.expand(m, -1), std=std.expand(m, -1))
device = torch.device(f"cuda:{device_ids[0]}" if torch.cuda.is_available() else "cpu")
if torch.cuda.device_count() > 1:
try:
device_ids
except NameError:
device_ids = list(range(torch.cuda.device_count()))
model = torch.nn.DataParallel(model, device_ids=device_ids).to(device)
else:
model = model.to(device)
loss_type = 'mse'
criterion = masked_mse_loss if loss_type == 'mse' else masked_huber_loss
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
if scheduler_type == 'steplr':
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, schedule_interval, gamma=0.95)
elif scheduler_type == 'cosine':
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=len(trainloader)*epochs)
elif scheduler_type == 'cosine_warm':
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=int(len(trainloader)*epochs*0.05),
num_training_steps=len(trainloader)*epochs,
)
else:
raise ValueError('Unknown scheduler')
scaler = torch.cuda.amp.GradScaler(enabled=amp)
Using simple batchnorm instead of domain specific batchnorm
INFO:xpert:Missing keys: 0 | Unexpected keys: 0
10. Training Loop and Validation
[13]:
epochs
[13]:
20
[16]:
best_val_loss = float('inf')
best_model = None
patience = 0
early_stop = epochs
train_metrics_list, train_metrics_pert_list = [], []
val_metrics_list, val_metrics_pert_list = [], []
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train_loader = pert_data.dataloader["train_loader"]
valid_loader = pert_data.dataloader["val_loader"]
train(model, train_loader)
val_loss, val_mre = evaluate(model, valid_loader)
elapsed = time.time() - epoch_start_time
logger.info("-" * 89)
logger.info(f"| end of epoch {epoch:3d} | time: {elapsed:5.2f}s | valid loss/mse {val_loss:5.4f} |")
logger.info("-" * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = copy.deepcopy(model)
logger.info(f"Best model with score {best_val_loss:5.4f}")
patience = 0
torch.save(best_model.state_dict(), save_root / "model_best.pt")
else:
patience += 1
if patience >= early_stop:
logger.info(f"Early stop at epoch {epoch}")
break
if np.isnan(val_loss):
logger.warning(f"NaN loss detected at epoch {epoch}, stopping training")
break
# Optional metric collection (costly)
train_res = eval_perturb_new(train_loader, model, device)
val_res = eval_perturb_new(valid_loader, model, device)
if train_res is not None:
train_metrics, train_metrics_pert = compute_metrics(train_res)
train_metrics_list.append(train_metrics)
train_metrics_pert_list.append(train_metrics_pert)
if val_res is not None:
val_metrics, val_metrics_pert = compute_metrics(val_res)
val_metrics_list.append(val_metrics)
val_metrics_pert_list.append(val_metrics_pert)
if scheduler_type == 'steplr':
scheduler.step()
37%|███▋ | 100/272 [00:21<00:36, 4.72it/s]INFO:xpert:| epoch 1 | 100/272 batches | lr 0.000010 | ms/batch 215.50 | loss 1.00488 | mse 1.00488 |
74%|███████▎ | 200/272 [00:42<00:15, 4.65it/s]INFO:xpert:| epoch 1 | 200/272 batches | lr 0.000010 | ms/batch 213.78 | loss 0.99828 | mse 0.99828 |
100%|██████████| 272/272 [00:58<00:00, 4.68it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 1 | time: 59.90s | valid loss/mse 0.9853 |
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:Best model with score 0.9853
37%|███▋ | 100/272 [00:21<00:36, 4.65it/s]INFO:xpert:| epoch 2 | 100/272 batches | lr 0.000010 | ms/batch 217.89 | loss 0.97153 | mse 0.97153 |
74%|███████▎ | 200/272 [00:43<00:15, 4.60it/s]INFO:xpert:| epoch 2 | 200/272 batches | lr 0.000010 | ms/batch 216.41 | loss 1.00774 | mse 1.00774 |
100%|██████████| 272/272 [00:58<00:00, 4.64it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 2 | time: 60.42s | valid loss/mse 0.9806 |
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:Best model with score 0.9806
37%|███▋ | 100/272 [00:21<00:37, 4.63it/s]INFO:xpert:| epoch 3 | 100/272 batches | lr 0.000010 | ms/batch 217.97 | loss 1.00138 | mse 1.00138 |
74%|███████▎ | 200/272 [00:43<00:15, 4.63it/s]INFO:xpert:| epoch 3 | 200/272 batches | lr 0.000009 | ms/batch 216.29 | loss 0.95521 | mse 0.95521 |
100%|██████████| 272/272 [00:58<00:00, 4.63it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 3 | time: 60.46s | valid loss/mse 0.9823 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.61it/s]INFO:xpert:| epoch 4 | 100/272 batches | lr 0.000009 | ms/batch 218.43 | loss 1.00173 | mse 1.00173 |
74%|███████▎ | 200/272 [00:43<00:15, 4.66it/s]INFO:xpert:| epoch 4 | 200/272 batches | lr 0.000009 | ms/batch 216.12 | loss 0.94610 | mse 0.94610 |
100%|██████████| 272/272 [00:58<00:00, 4.63it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 4 | time: 60.45s | valid loss/mse 0.9963 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.65it/s]INFO:xpert:| epoch 5 | 100/272 batches | lr 0.000009 | ms/batch 217.11 | loss 0.96026 | mse 0.96026 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 5 | 200/272 batches | lr 0.000009 | ms/batch 215.90 | loss 0.95277 | mse 0.95277 |
100%|██████████| 272/272 [00:58<00:00, 4.64it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 5 | time: 60.30s | valid loss/mse 0.9906 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.59it/s]INFO:xpert:| epoch 6 | 100/272 batches | lr 0.000008 | ms/batch 217.74 | loss 0.95488 | mse 0.95488 |
74%|███████▎ | 200/272 [00:43<00:15, 4.61it/s]INFO:xpert:| epoch 6 | 200/272 batches | lr 0.000008 | ms/batch 216.65 | loss 0.94644 | mse 0.94644 |
100%|██████████| 272/272 [00:58<00:00, 4.63it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 6 | time: 60.49s | valid loss/mse 0.9987 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.62it/s]INFO:xpert:| epoch 7 | 100/272 batches | lr 0.000007 | ms/batch 218.08 | loss 0.91249 | mse 0.91249 |
74%|███████▎ | 200/272 [00:43<00:15, 4.62it/s]INFO:xpert:| epoch 7 | 200/272 batches | lr 0.000007 | ms/batch 216.93 | loss 0.94172 | mse 0.94172 |
100%|██████████| 272/272 [00:58<00:00, 4.63it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 7 | time: 60.54s | valid loss/mse 0.9965 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:36, 4.65it/s]INFO:xpert:| epoch 8 | 100/272 batches | lr 0.000007 | ms/batch 217.24 | loss 0.94788 | mse 0.94788 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 8 | 200/272 batches | lr 0.000006 | ms/batch 216.07 | loss 0.91103 | mse 0.91103 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 8 | time: 60.28s | valid loss/mse 1.0237 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 9 | 100/272 batches | lr 0.000006 | ms/batch 216.84 | loss 0.90037 | mse 0.90037 |
74%|███████▎ | 200/272 [00:42<00:15, 4.63it/s]INFO:xpert:| epoch 9 | 200/272 batches | lr 0.000006 | ms/batch 215.30 | loss 0.93209 | mse 0.93209 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 9 | time: 60.19s | valid loss/mse 0.9994 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 10 | 100/272 batches | lr 0.000005 | ms/batch 216.54 | loss 0.92763 | mse 0.92763 |
74%|███████▎ | 200/272 [00:42<00:15, 4.65it/s]INFO:xpert:| epoch 10 | 200/272 batches | lr 0.000005 | ms/batch 215.16 | loss 0.90561 | mse 0.90561 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 10 | time: 60.21s | valid loss/mse 1.0008 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 11 | 100/272 batches | lr 0.000004 | ms/batch 217.25 | loss 0.91454 | mse 0.91454 |
74%|███████▎ | 200/272 [00:43<00:15, 4.69it/s]INFO:xpert:| epoch 11 | 200/272 batches | lr 0.000004 | ms/batch 215.04 | loss 0.93146 | mse 0.93146 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 11 | time: 60.23s | valid loss/mse 1.0044 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 12 | 100/272 batches | lr 0.000003 | ms/batch 217.02 | loss 0.93312 | mse 0.93312 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 12 | 200/272 batches | lr 0.000003 | ms/batch 215.48 | loss 0.88561 | mse 0.88561 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 12 | time: 60.21s | valid loss/mse 1.0112 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 13 | 100/272 batches | lr 0.000003 | ms/batch 217.25 | loss 0.92406 | mse 0.92406 |
74%|███████▎ | 200/272 [00:43<00:15, 4.63it/s]INFO:xpert:| epoch 13 | 200/272 batches | lr 0.000002 | ms/batch 215.73 | loss 0.89997 | mse 0.89997 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 13 | time: 60.28s | valid loss/mse 1.0017 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:36, 4.68it/s]INFO:xpert:| epoch 14 | 100/272 batches | lr 0.000002 | ms/batch 217.04 | loss 0.90202 | mse 0.90202 |
74%|███████▎ | 200/272 [00:43<00:15, 4.63it/s]INFO:xpert:| epoch 14 | 200/272 batches | lr 0.000002 | ms/batch 215.50 | loss 0.93869 | mse 0.93869 |
100%|██████████| 272/272 [00:58<00:00, 4.66it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 14 | time: 60.15s | valid loss/mse 1.0029 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 15 | 100/272 batches | lr 0.000001 | ms/batch 217.00 | loss 0.91758 | mse 0.91758 |
74%|███████▎ | 200/272 [00:43<00:15, 4.63it/s]INFO:xpert:| epoch 15 | 200/272 batches | lr 0.000001 | ms/batch 215.93 | loss 0.90154 | mse 0.90154 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 15 | time: 60.30s | valid loss/mse 1.0071 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.63it/s]INFO:xpert:| epoch 16 | 100/272 batches | lr 0.000001 | ms/batch 217.23 | loss 0.91806 | mse 0.91806 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 16 | 200/272 batches | lr 0.000001 | ms/batch 215.36 | loss 0.90915 | mse 0.90915 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 16 | time: 60.23s | valid loss/mse 1.0055 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.62it/s]INFO:xpert:| epoch 17 | 100/272 batches | lr 0.000000 | ms/batch 217.45 | loss 0.92557 | mse 0.92557 |
74%|███████▎ | 200/272 [00:43<00:15, 4.63it/s]INFO:xpert:| epoch 17 | 200/272 batches | lr 0.000000 | ms/batch 217.65 | loss 0.90771 | mse 0.90771 |
100%|██████████| 272/272 [00:58<00:00, 4.63it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 17 | time: 60.52s | valid loss/mse 1.0058 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.64it/s]INFO:xpert:| epoch 18 | 100/272 batches | lr 0.000000 | ms/batch 217.61 | loss 0.90280 | mse 0.90280 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 18 | 200/272 batches | lr 0.000000 | ms/batch 215.64 | loss 0.91027 | mse 0.91027 |
100%|██████████| 272/272 [00:58<00:00, 4.64it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 18 | time: 60.39s | valid loss/mse 1.0067 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.63it/s]INFO:xpert:| epoch 19 | 100/272 batches | lr 0.000000 | ms/batch 218.07 | loss 0.92397 | mse 0.92397 |
74%|███████▎ | 200/272 [00:43<00:15, 4.62it/s]INFO:xpert:| epoch 19 | 200/272 batches | lr 0.000000 | ms/batch 216.18 | loss 0.89055 | mse 0.89055 |
100%|██████████| 272/272 [00:58<00:00, 4.64it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 19 | time: 60.42s | valid loss/mse 1.0067 |
INFO:xpert:-----------------------------------------------------------------------------------------
37%|███▋ | 100/272 [00:21<00:37, 4.63it/s]INFO:xpert:| epoch 20 | 100/272 batches | lr 0.000000 | ms/batch 217.85 | loss 0.92940 | mse 0.92940 |
74%|███████▎ | 200/272 [00:43<00:15, 4.64it/s]INFO:xpert:| epoch 20 | 200/272 batches | lr 0.000000 | ms/batch 214.97 | loss 0.87172 | mse 0.87172 |
100%|██████████| 272/272 [00:58<00:00, 4.65it/s]
INFO:xpert:-----------------------------------------------------------------------------------------
INFO:xpert:| end of epoch 20 | time: 60.27s | valid loss/mse 1.0068 |
INFO:xpert:-----------------------------------------------------------------------------------------
11. Final Evaluation and Save Artifacts
[17]:
# Save best model and evaluate on test set
torch.save(best_model.state_dict(), save_root / "model_best.pt")
test_loader = pert_data.dataloader["test_loader"]
test_res = eval_perturb_new(test_loader, best_model, device)
# Save results
model_prefix = f'lr_{lr}_cotrain_mode'
result_dir = save_root / f'result_{model_prefix}'
result_dir.mkdir(parents=True, exist_ok=True)
import pickle
pickle.dump(test_res, open(result_dir / 'test_res.pkl', 'wb'))
if len(train_metrics_list) > 0:
pickle.dump(train_metrics_list, open(result_dir / 'train_metrics_list.pkl', 'wb'))
pickle.dump(train_metrics_pert_list, open(result_dir / 'train_metrics_pert_list.pkl', 'wb'))
pickle.dump(val_metrics_list, open(result_dir / 'val_metrics_list.pkl', 'wb'))
pickle.dump(val_metrics_pert_list, open(result_dir / 'val_metrics_pert_list.pkl', 'wb'))
# Optional plotting if metrics were collected
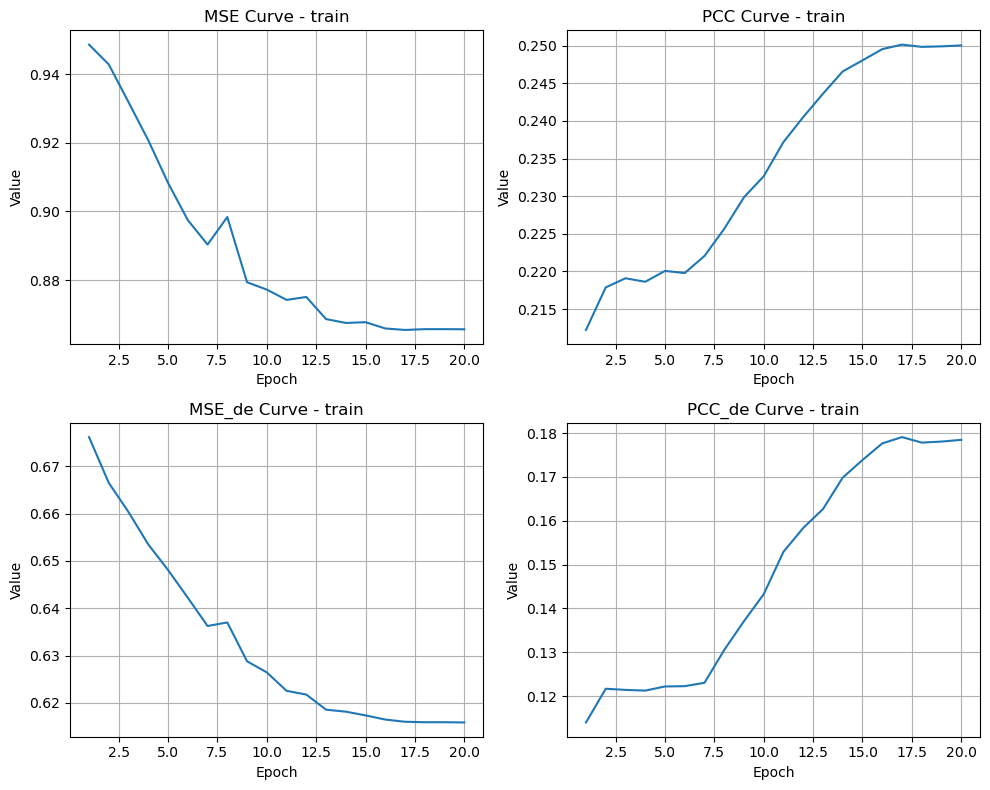
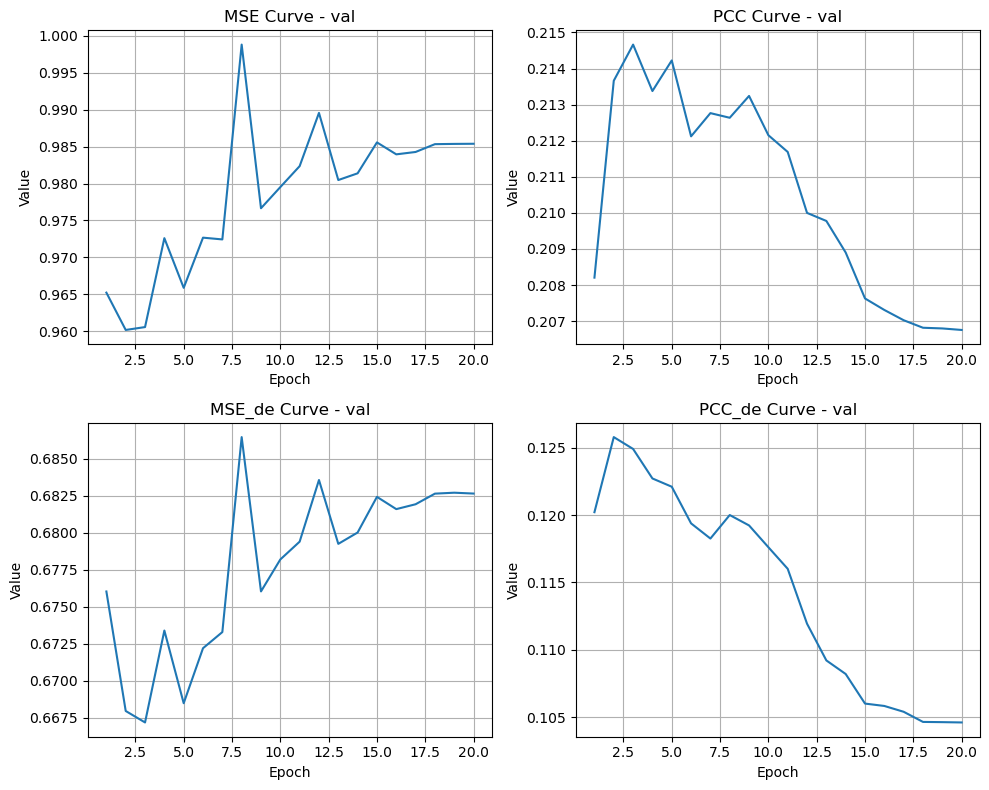
if len(train_metrics_list) > 0:
try:
merge_plot(train_metrics_list, 'train', str(result_dir / 'train.png'))
merge_plot(val_metrics_list, 'val', str(result_dir / 'val.png'))
except Exception as e:
logger.warning(f"Plotting skipped: {e}")
# Free CUDA cache
torch.cuda.empty_cache()